

PostgreSQL Episode 2 : L’architecture
17/10/2018
Données
Dans ce deuxième épisode consacré à PostgreSQL, nous allons découvrir l’architecture de PostgreSQL (structure, utilisateurs, schémas, SEARCH_PATH, tablespaces, stockage, transactions, MVCC…).
Cet article et cette vidéo constituent la 2ème partie d'une série sur PostgreSQL. L'épisode 1 sur l'ecosystème PostgreSQL est disponible ici.
Inscrivez-vous à notre liste de diffusion pour recevoir les prochains épisodes dans votre boite email !
L'architecture du moteur Postgres
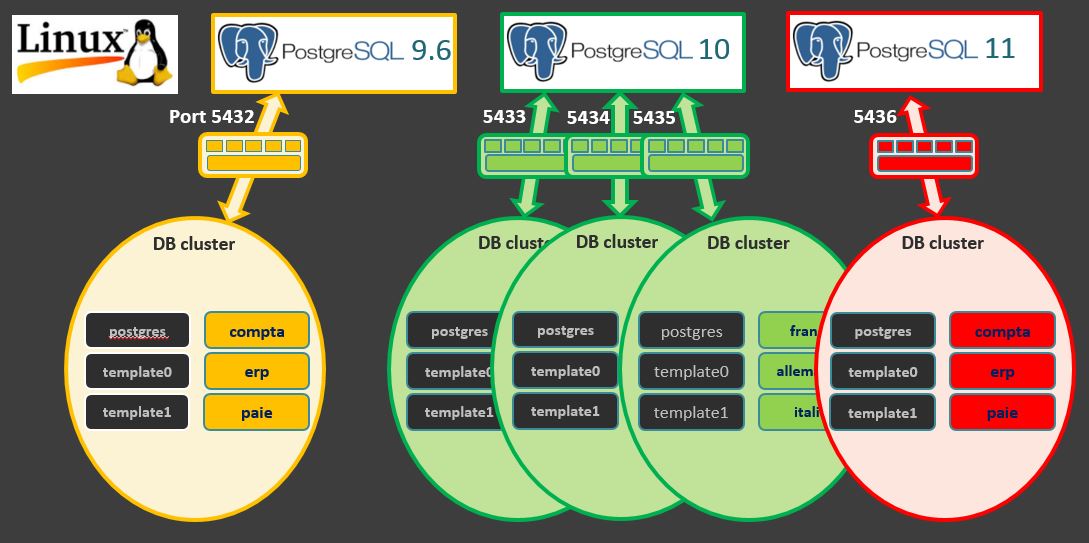
Un serveur Linux peut héberger une ou plusieurs versions de PostgreSQL. Dans cet exemple, nous avons installé les versions 9.6, 10 et 11 de Postgres.
Une instance postgres gère toujours les données d'un seul DB cluster. Un DB cluster est un ensemble de bases de données stocké à un même emplacement dans le système de fichiers. La connexion à chaque instance est faite à travers un numéro de port dédié à la création du DB Cluster.
Cela ressemble beaucoup à l’architecture Multi-Tenants d’Oracle 12c et à l’architecture native de Microsoft SQL Server.
Chaque DB Cluster peut contenir de très nombreuses bases de données.
Chaque DB Cluster contient une base de données nommée postgres, qui a pour but d'être la base de données où se connectent certains outils ou les DBA.
Deux autres bases de données sont créées à l'intérieur de chaque groupe lors de l'initialisation du Cluster DB. Elles sont appelées template0 et template1. Comme le nom le suggère, elles seront utilisées comme modèle pour les bases de données créées ensuite.
Zoom sur le moteur Postgres
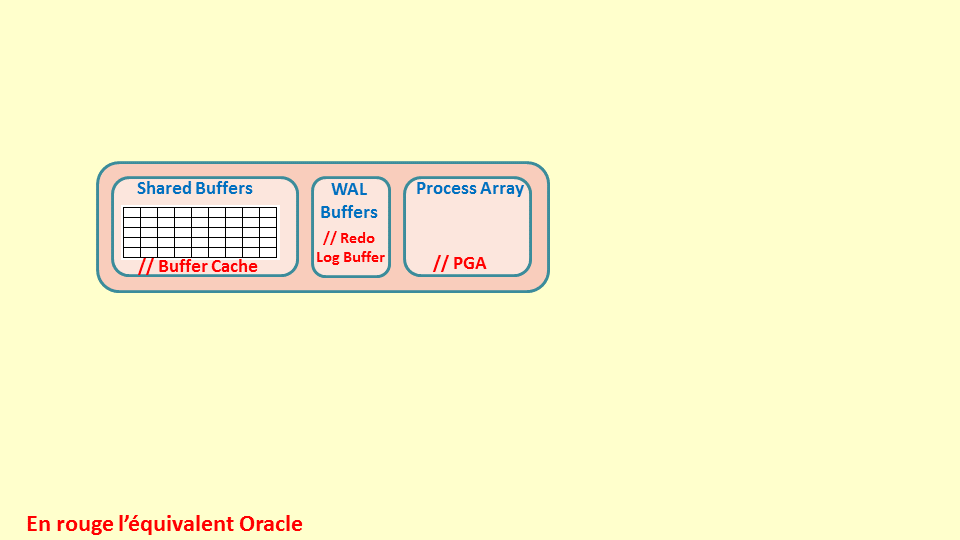
Pour qu’un groupe de bases de données (DB Cluster) puisse être utilisé, une instance PostgreSQL doit être démarrée.
Au lancement de l’instance, Postgres alloue une mémoire partagée entre tous les process qui vont être lancés pour cette instance.
Cet espace mémoire contient :
- Le Shared Buffers, qui est une mémoire cache contenant les blocs de tables et d’index Postgres les plus accédés (comme le fait Oracle avec le Buffer Cache de sa SGA)
- Le WAL Buffers est un buffer contenant les entrées du journal des transactions. Il contient toutes les modifications effectuées sur les tables et index des bases de ce DB Cluster (comme le fait Oracle avec le Redo Log Buffer). Ce buffer va être vidé au fur et à mesure dans les fichiers WAL (Write-Ahead Logging). Ce mécanisme permet de garantir de ne pas perdre de données en cas d’arrêt brutal de l’instance ou du serveur. Un mécanisme de Checkpoint y est associé.
- Le Process Array correspond à l’espace mémoire de travail, dont les tris, pour les process utilisateurs.
Les fichiers de l’instance
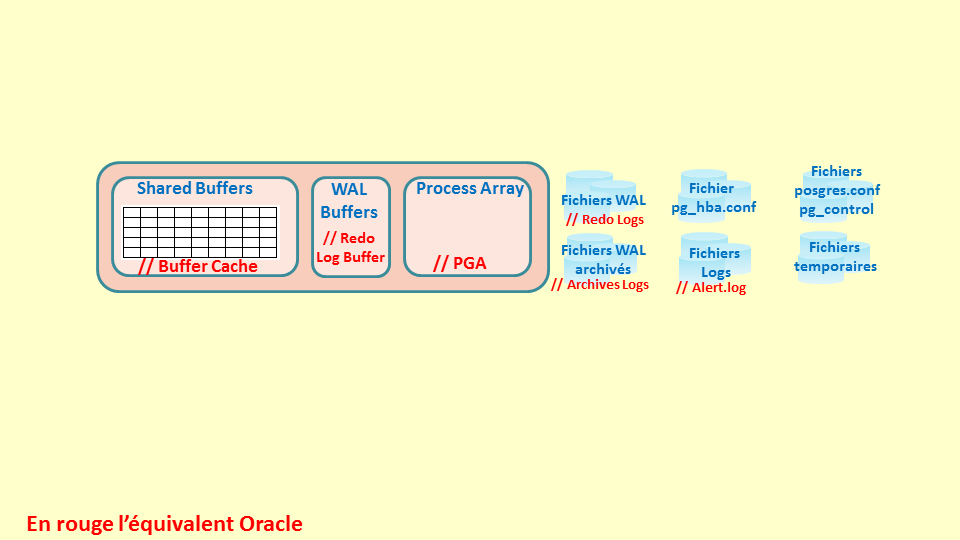
Les fichiers WAL contiennent la journalisation des transactions effectuées sur les bases d’un DB Cluster. Ils sont alimentés à partir du WAL Buffers. Il permettent, en cas d’arrêt brutal du serveur, de redémarrer le groupe de bases de données PostgreSQL et de rejouer les transactions à partir du dernier checkpoint valide. Cela correspond aux fichiers Redo Logs d’Oracle.
Une fois remplis, les fichiers WAL peuvent être archivés si l’instance fonctionne en mode Archive. Cela correspond aux fichiers Archives Logs d’Oracle.
Le fichier ph_hba_conf permet de configurer des autorisations de connexions.
Les fichiers Logs contiennent des informations sur le fonctionnement de cette instance. Il correspondent au fichier alert.log d’Oracle.
Le fichier posgres.conf contient les paramètres pour l’instance.
Le Fichier pg_control contient des informations permettant à l’instance d’ouvrir un groupe de bases de données et d’en assurer l’intégrité.
Des fichiers temporaires sont créés par l’instance pour effectuer des tris, créer des index, etc…
Cette image présente les process de l’instance.
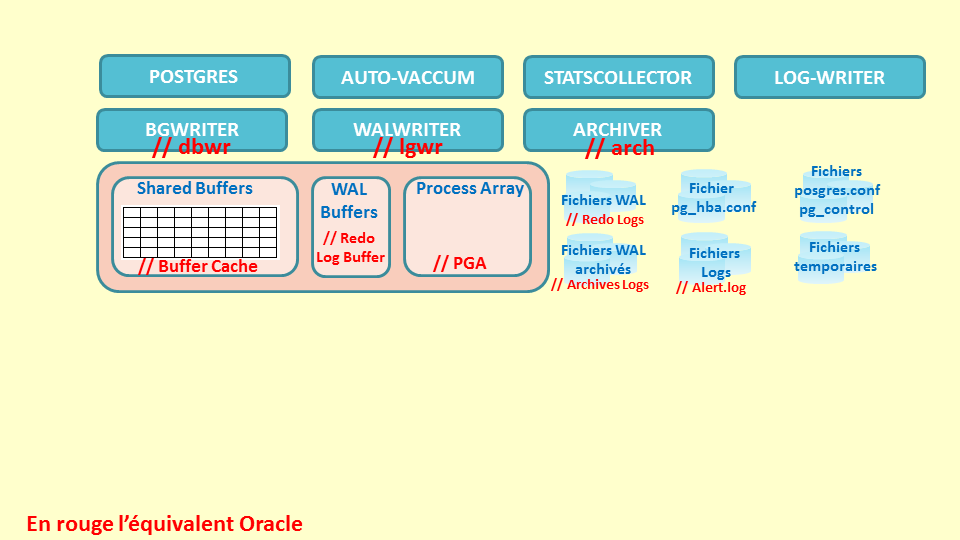
Postgres est considéré comme le process principal de PostgreSQL. Il est aussi appelé postmaster. C’est lui qui lance et surveille les processus Background du serveur PostgreSQL. Il écoute également toutes les connexions entrantes et lance un process par session.
- BGWRITER est chargé d’écrire les blocs modifiés dans la mémoire (Shared Buffers) vers les fichiers de données tables ou index
- AUTO-VACCUM gère et supervise le nettoyage des tables et lance le calcul des statistiques.
- WALWRITER est chargé d’écrire dans les fichiers WAL le contenu du « WAL Buffers ». Cette écriture survient soit au moment d’un COMMIT, soit si le WAL Buffers est trop rempli.
- STATSCOLLECTOR a pour but de récupérer certaines informations sur l’activité des processus postgres. Ce processus peut être désactivé.
- ARCHIVER effectue l'archivage des journaux de transactions (fichiers WAL) si le mode archive est activé.
- LOG-WRITER redirige les messages (informations, avertissements, erreurs) des différents processus postgres vers les fichiers logs.
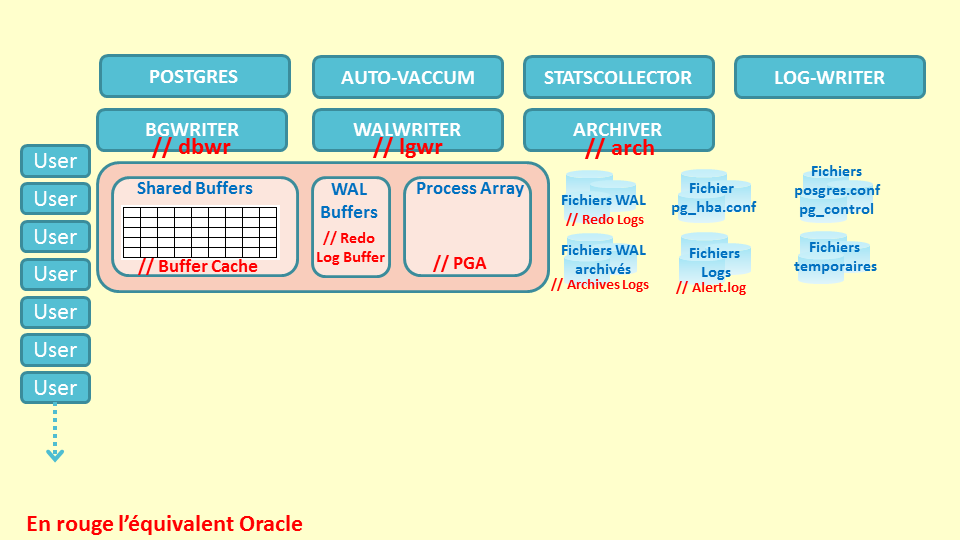
Les process USER sont créés pour chaque session ouverte dans l’instance.
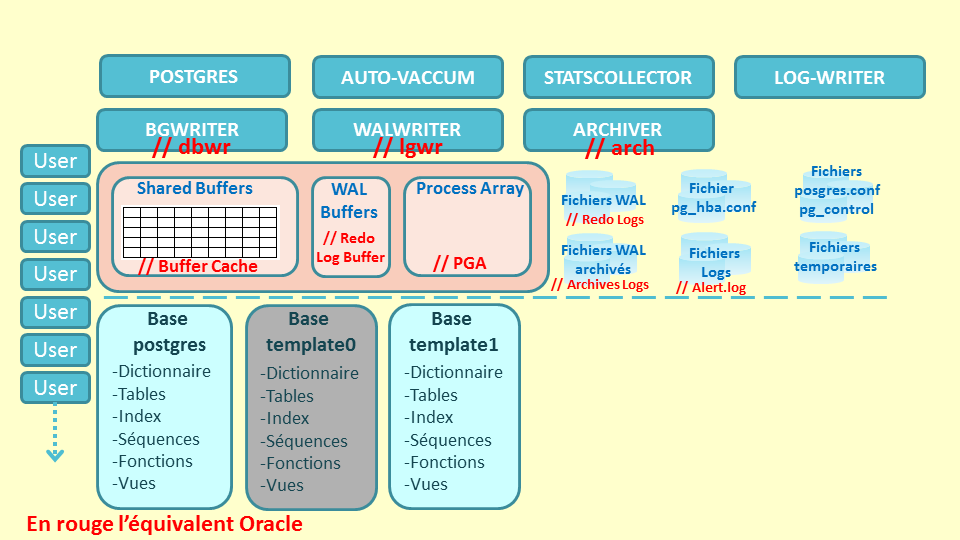
Trois bases son créées par défaut :
- La base Postgres est utilisé pour la connexion de certains outils ou du DBA.
- Sous Postgres, la création d’une base se fait obligatoirement à partir d’une base template du même DB Cluster.
- La base template0 contient la structure minimum d’une base et elle ne peut pas être supprimée.
- La base template1 est une copie de la base template0. On peut ajouter des tables et des fonctions qui seraient nécessaires à toutes les autres bases créées ensuite à partir de cette base template1.
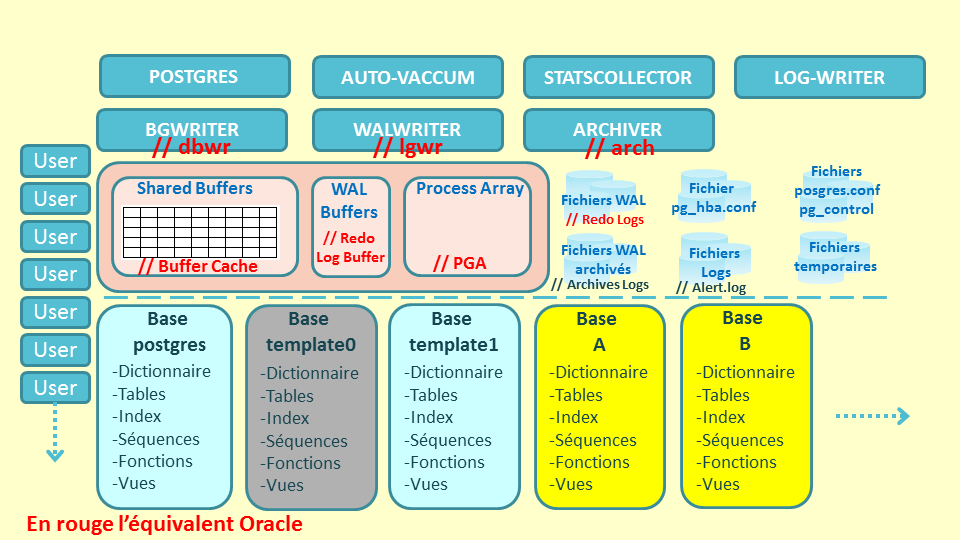
Des bases de données applicatives peuvent fort heureusement être ajoutées au DB Cluster :
Nous remarquons ici que deux bases ont été ajoutées : A et B.
7 points sur les utilisateurs PostgreSQL
- Les utilisateurs Postgres sont créés au niveau du DB Cluster ;
- Il existe un Super Utilisateur (par défaut POSTGRES) ;
- Il est possible de créer des utilisateurs supplémentaires ;
- Les utilisateurs sont définis au niveau du DB Cluster
- Les utilisateurs peuvent créer des tables dans plusieurs bases ;
- Il est possible de paramétrer des droits de connexion base par base ;
- Cela peut poser un problème si deux logiciels veulent créer leurs tables dans deux bases différentes avec le même nom d’utilisateur, car il y aurait un seul mot de passe, donc des problèmes de sécurité !
… et 7 points sur les schémas
- La notion de schéma est indépendante de la notion d’utilisateur ;
- Un schéma appartient à une base ;
- Il peut exister le même nom de schéma dans différentes bases d’un même DB Cluster; ces schémas seront indépendants ;
- Une table fait obligatoirement partie d’un schéma ;
- Il existe un schéma PUBLIC par défaut dans chaque base ;
- Une table appartient obligatoirement à un propriétaire ;
- Il existe un SEARCH_PATH
La variable SEARCH_PATH, une notion très importante
La variable PATH sous Linux ou Windows permet de lancer un programme sans trop savoir où il se trouve, à condition que son répertoire soit dans la variable PATH.
Postgres utilise le même concept pour trouver les tables. La variable SEARCH_PATH assignée à la connexion est modifiable. Elle liste le ou les schémas où peuvent se trouver les tables utilisées dans les ordres SQL.
Etant donné que Postgres ne possède pas la notion de synonymes, le SEARCH_PATH a son utilité.
Cette méthode est très pratique mais aussi très dangereuse. En effet, en fonction des schémas listés dans le SEARCH_PATH et de leur ordre, les résultats peuvent être complétement différents… Mais nous pouvons paramétrer ce SEARCH_PATH fort heureusement.
Un exemple de paramétrage du SEARCH_PATH à 00:11:55
Les tablespaces et leur structure
Pour étudier les tablespaces, prenons deux exemples sous Oracle et PostgreSQL.
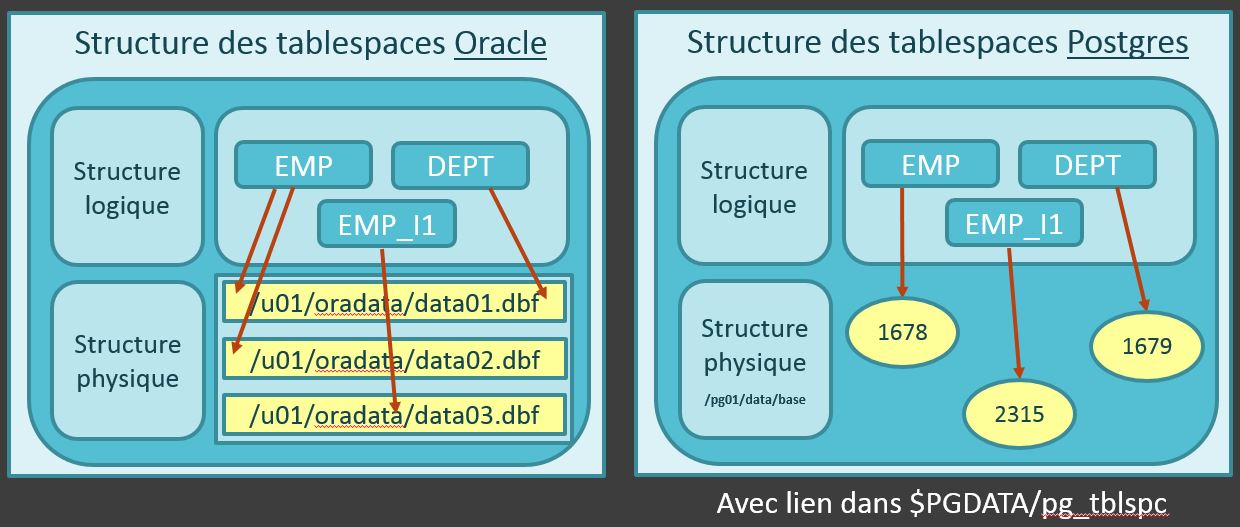
A gauche, la représentation d’un tablespaces ORACLE, avec 2 tables et un index stockés dans celui-ci, ainsi que les 3 Datafiles constituant ce tablespace. Tous les DBAs Oracle connaissent bien cela.
Dans Postgres, un tablespace est associé à un répertoire.
Il existe un tablespace par défaut dans une installation de Postgres, associé à un répertoire. Dans ce répertoire, des sous-répertoires sont créés pour chaque base. Les tables et index de chaque base seront créées dans leurs sous-répertoires respectifs. Vous remarquez que chaque table ou index est stocké sous forme de fichiers individuels, avec un numéro. Nous y reviendrons...
Si nous voulons créer un nouveau tablespace, nous devons créer un répertoire dans un File System puis lancer la commande CREATE TABLESPACE en précisant : le nom du Tablespace et le répertoire associé.
Postgres va alors créer un lien symbolique dans le répertorie $PGDATA/pg_tblspc pour pointer sur le répertoire du nouveau TABLESPACE.
Le stockage des tables, index et lignes
Chaque table est stockée dans un fichier autonome.
Les tables de plus d’un Go sont découpées en plusieurs fichiers d’un Go au maximum.
Il en est de même pour les Index.
Les fichiers associés aux tables et index sont stockés « dans » un tablespace, c’est-à-dire dans le répertoire associé au tablespace.
Le nom des fichiers associés aux tables et index est numérique…
Une fonction SQL de Postgres ainsi qu’un utilitaire permettent de connaître le noms des tables et index en fonction de leur numéro. (Voir l’exemple dans la vidéo à 00:15:16)
Les transactions et les propriétés ACID
Une transaction est un groupe de commandes SQL dont les résultats seront :
- rendus entièrement visibles pour le reste du système lorsque la transaction est validée (COMMIT)
- ou enlevés de la base, si la transaction est annulée (ROLLBACK)
Pour respecter les propriétés ACID, les transactions doivent être atomiques, cohérentes, isolées et durables.
A ce jour, Postgres ne prend pas en charge les transactions distribuées, de sorte que toutes les commandes d'une transaction sont forcément exécutées dans la même instance et dans la même base PostgreSQL.
Pour plus d’infos sur les propriétés ACID, allez à 00:18:38
Multiversion Concurrency Control (MVCC)
Le respect des normes ACID oblige de pouvoir visualiser une ligne dans une version plus ancienne. C’est ce que l’on appelle le Multiversion Concurrency Control (MVCC) ou Lecture Consistente.
Pour mémoire, Oracle utilise la fonctionnalité UNDO (auparavant ROLLBACK SEGMENTS) pour permettre d’accéder à des lignes d’une version précédente ou aux lignes en cours de modification.
Il n’existe pas de système de type UNDO, sous Postgres mais un autre système
Exemple à 00:20:02
Pour en savoir plus , découvrez notre guide pratique sur la meilleure architecture de données pour votre entreprise pour les DSI.
Si vous voulez en savoir plus, inscrivez-vous à notre liste de diffusion pour recevoir directement les prochains épisodes dans votre boite email !
Les 2 prochains épisodes consacrés à PostgreSQL seront diffusés sur YouTube et notre blog :
- 25/10 - Comment sauvegarder les bases PostgreSQL ?
- 15/11 - Comment superviser les environnements PostgreSQL ?
Pour aller plus loin

Blog
Big Data
Data
Données
Publié le 29/07/2024
La transformation numérique des collectivités : un enjeu majeur pour l'avenir des territoires
Dans un monde de plus en plus digitalisé, les collectivités territoriales sont confrontées à un défi de taille : s'adapter aux [...]
Lire la suite

