
Oracle Database In-Memory - partie 3
05/06/2014
Business
Données
Nous avons publié récemment un premier billet et un deuxième billet qui détaillent la nouvelle fonctionnalité Oracle Database In-Memory 12c, à partir de la keynote de Larry Ellison, présentée à l'Oracle Open World 2013. Pour vous faire patienter jusqu'au lancement en France par Oracle de cette option révolutionnaire le 18 juin, à Paris, où Gilles Knoery, Directeur Général de Digora, sera interviewé, voici le troisième billet.
Rappel : depuis quelques mois, Digora a eu le privilège de tester cette nouvelle option dans le cadre du programme Beta Testing organisé par Oracle.
1. Démonstration d'In-Memory Database
A ce stade de sa Keynote, Larrry Ellison invite Juan Loueza à venir sur le podium pour une démonstration d'Oracle In-Memory Database 12c.


Examinons une première démonstration, basée sur une application utilisant des requêtes analytiques sur, tout d’abord, un serveur équipé de deux processeurs standards Intel. Je vais vous montrer comment cela fonctionne aujourd’hui, et comment cela fonctionnera bientôt. Cela concerne tout particulièrement les DBA et les développeurs d’applications car cela va changer la façon de faire. Il s’agit d’une technologie qui va changer les règles du jeu. Détaillons la démonstration. Nous avons une table de 3 milliards de lignes. C’est sur cette table que nous allons lancer une requête. Pour rendre les choses plus intéressantes,nous allons utiliser des données réelles, les recherches que les gens ont fait sur Wikipedia et nous allons les mettre dans cette table de 3 milliards de lignes. Donc, chaque ligne de cette table correspond à une recherche faite par un utilisateur dans le site Wikipedia durant les dernières semaines d’août. Je vais vous montrer comment vous pouvez analyser ces données. Nous allons rechercher, pour des expressions précisées, et pour des périodes de temps spécifiées, combien de recherches ont eu lieu et nous allons les représenter graphiquement avec l’échelle du temps. Je vais vous montrer comment on fait cela maintenant et comment on fera cela dans le futur. Il s’agit d’une démonstration très simple. Je n’ai qu’à taper un mot à rechercher et nous allons obtenir le nombre d’occurrences et une représentation graphique. Comment faisons nous cela maintenant ? Quelqu’un vient me voir et me dit : voici une table de 3 milliards de lignes. Je veux exécuter des requêtes analytiques sur cette table. Tout d’abord, je dirai : OK. J’aimerais savoir quels types de requêtes seront exécutées sur cette table. Et je vais créer des index appropriés pour ces requêtes. Et les résultats sont assez rapides. Donc, avec la technologie actuelle, si vous savez ce qui va être recherché et que vous créez les index appropriés, c’est très rapide. C’est ce que je voulais vous montrer tout d’abord. Mais si vous créez les mauvais index, cela n’ira pas aussi vite ! C’est comme cela. Ainsi, nous avons notre table. Je vais saisir un expression de recherche qui est « I have a dream ».
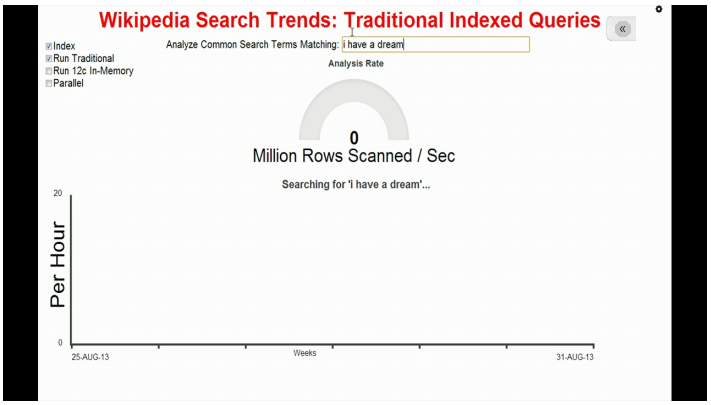
Examinez bien les cases à cocher qui sont sélectionnées en haut à gauche de l’écran :

Nous allons utiliser un index et l'approche traditionnelle (pas d'Oracle In-Memory). C’est une démonstration réelle, en direct. Vous pouvez venir chez nous, essayer vous-mêmes et contrôler les bénéfices vous-mêmes. Alors nous allons lancer la recherche sur cette expression. Nous avons chargé les consultations sur Wikipedia pour la dernière semaine d’août : c’était le 50ème anniversaire du discours « I have a dream ».

Comme vous le voyez, il y a eu 415000 recherches pour ce terme sur 3 milliards de recherche en tout. Et en plus vous avez un graphique sur l’axe du temps pendant cette semaine ; Vous remarquez que le 29 août, qui est le 50ème anniversaire du discours, nous avons une forte croissance de recherche pour cette recherche. La chose importante, de notre point de vue, c’est que, comme vous le constatez, la requête s’exécute à la vitesse de 2 milliards, 2 mille millions de lignes par seconde, sur une table de 3 miliards de lignes. Donc cela a duré une seconde et demi. Ainsi, avec la technologie actuelle, l’exécution d’une requête analytique qui retourne environ un demi-million de lignes sur une table de 3 milliards de ligne dure environ une seconde et demi. Les résultats sont obtenus de façon plutôt rapide. Passons maintenant à l’étape suivante. Que se passerait-il si nous n’avions pas d’index ? Si moi ou quelqu’un d’autre lançait un autre type de requête ou si j’ai oublié de créer un index et que je dois lancer la requête sans bénéficier d’index… Bien, je vais désactiver l’index puis relancer la requête. Et voilà ce qui se passe cette fois. Nous avons déjà chargé des données de cette table dans le buffer cache traditionnel, le stockage en ligne traditionnel.
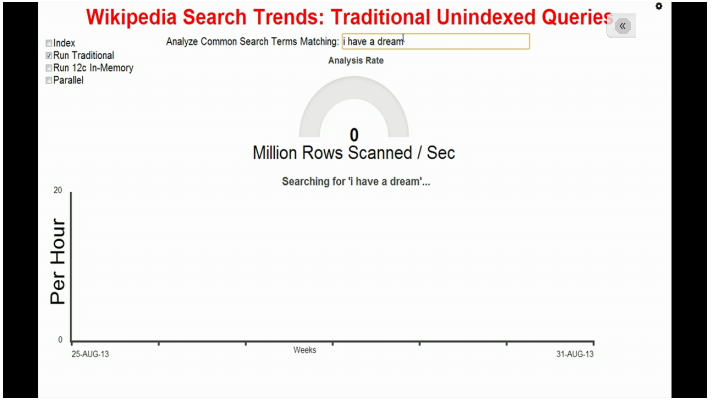
Examinez bien la seule case à cocher qui est sélectionné en haut à gauche de l’écran : on n'utilise plus d'index. On va balayer toute la table avec la technologie actuelle. Le balayage est en train de s’effectuer. Et vous voyez la progression car le travail est un peu lent : 5 millions de lignes par seconde. Cela prend du temps. Si vous divisez 3 milliards de lignes par 5 millions de lignes par seconde, cela fait… quelques minutes. Ce n’est pas trop amusant pour les utilisateurs. Les requêtes qui ne bénéficient pas d’index prennent du temps…
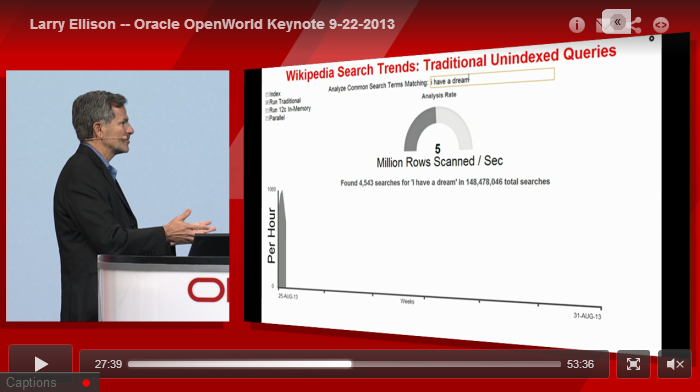
Voilà quelles sont les alternatives aujourd’hui et c’est ce qui se passe quand vous voulez vous passer d’index aujourd’hui. Car, comme vous l’avez mentionné, les index ont des inconvénients trop importants. Le premier est qu'ils rendent les mises à jour plus coûteuses. Et le second est qu’il faut savoir lesquels créer. Regardez, nous allons comparer maintenant. Nous allons activer notre option In-Memory 12c. Et nous allons lancer exactement la même requête.

Nous allons lancer la requête tout d’abord sur la méthode actuelle (en ayant toutes les lignes dans le Buffer Cacher en mémoire) et simultanément avec le format In-Memory. Vous allez pouvoir observer les différences.
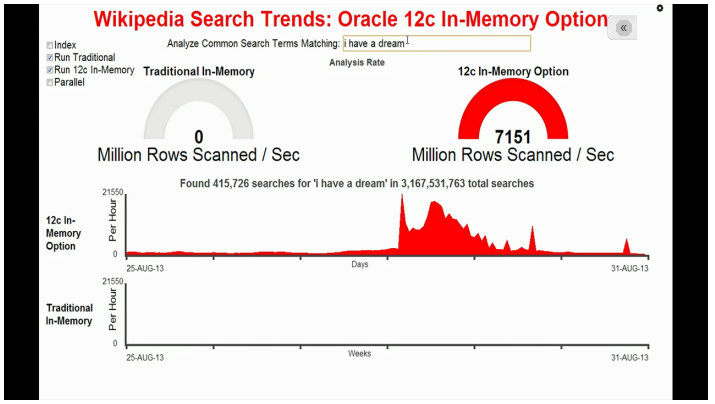
Bien, la requête avec In-Memory est terminée.
Et ce que vous pouvez voir ici, par rapport à notre option In-Memory, c’est que cette table a été traitée à 7151 millions de lignes par seconde, ou autrement dit 7 milliards de lignes par seconde. Beaucoup plus rapidement que ce que nous avions auparavant.

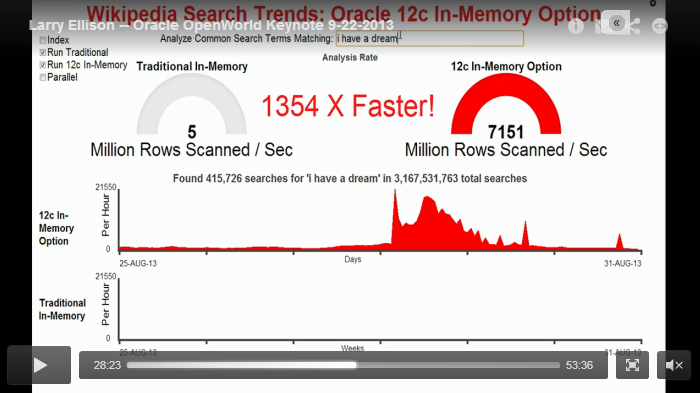
C’est très rapide ! Et, vous pouvez le voir, nous avons même fait le calcul : 1352 fois plus rapidement, c’est ce que vous obtenez. Ce qui est plus de 100 fois plus rapide. Un peu plus, Larry. C’est ce que nous pouvons obtenir aujourd’hui.
Actuellement, nous sous-estimons combien cette technologie est plus rapide dans certains cas. Et vous obtenez ceci
- sans avoir besoin de créer de nombreux index
- sans avoir l’overhead des index,
- sans avoir besoin de connaître à l’avance les requêtes qui seront lancées
- pratiquement sans overhead sur l’OLTP
Et c’est le grand changement qui vient avec la nouvelle version Oracle 12c et l’option In-Memory. Réellement fantastique. Merci Juan.

Donc j’aurais dû dire que les requêtes fonctionnent s’exécutent 1300 fois plus vite… Mais je pense que cela pourrait abîmer quelque peu ma crédibilité. Mais les nombres sont… assez étonnants. Et évidemment il s’agit ici d’une requête assez simple. Mais vous pouvez imaginer, lorsque les requêtes deviennent de plus en plus complexes et prennent de plus en plus de temps… Des choses qui durent une heure, maintenant s’exécutent en quelques secondes. C’est une amélioration dramatique pour les requêtes et les traitements analytiques.
2. Le In-Memory, le Flash et les disques

Laissez moi être clair sur le fait que la base entière n’a pas besoin d’être en mémoire. Vous n’avez pas besoin de mettre la base entière en mémoire pour tirer profit de l’option In-Memory. Vous pouvez avoir une bonne partie des données actives, une grande partie des données chaudes, utilisées actuellement pour accéder aux données, dans la mémoire DRAM. Vous pouvez aussi avoir une partie des données en Flash et enfin une partie des données sur disque. Par exemple, Oracle Exadata est conçu avec une hiérarchisation de mémoire pour en tirer avantage et les données migrent automatiquement de disque vers Flash vers DRAM, en fonction de vos type d’accès. C’est heuristique, il comprend et déplace les données en fonction de vos types d’accès. Et vous, ainsi, vous bénéficiez de la vitesse de l’option In-Memory, mais vous pouvez gérer des bases très très grandes et n’avez à payer qu’en fonction de l’espace disque nécessaire. Et bien sûr, au milieu de la hiérarchie, il y a le Flash.

3. La scalabilité horizontale et la scalabilité verticale
On peut faire de la scalabilité horizontale et de la scalabilité verticale avec ce système. Donc, Exadata est une architecture de type scalabilité horizontale, mais vous pouvez utiliser une configuration RAC sur des serveurs courants, et vous faites de la scalabilité horizontale sur cette technologie. Et, vous le savez, RAC fonctionne, et les données sont partitionnées entre, les segments sont partitionnés entre les serveurs. Nous découpons les requêtes et nous les envoyons à la machine qui possède les données. Et nous faisons cela très très rapidement dans le cas d’Exadata. Les machines Exadata sont rattachées ensemble avec Infiniband. Et nous avons un protocole spécial de communications, un logiciel que nous avons écrit pour obtenir des échanges inter-machines très très rapides, pour notre architecture de type scalabilité horizontale. Nous avons un protocole « direct-to-wire », « Infiniband wire », pour rendre ceci particulièrement rapide sur Exadata. Et bien sûr, Exadata dispose de DRAM, flash et disque. Des I/Os très très rapides… Donc, la scalabilité horizontale fonctionne, que vous utilisiez des serveurs standards ou que vous utilisiez Exadata. A nouveau, le In-Memory fonctionne avec tout, y compris Oracle RAC.

Vous pouvez aussi faire de la scalabilité verticale. Vous pouvez utiliser un gros serveur SMP, avec beaucoup de mémoire, pour exécuter vos gros traitements en mémoire. Vous pouvez faire du Scale-Up avec l’option In-Memory.

Ainsi, comme Juan vient de le démontrer, des améliorations énormes dans les requêtes simples, les jointures complexes, les créations d’états, la scalabilité horizontale, la scalabilité verticale, toutes vos possibilités de Recovery et de disponibilité fonctionnent exactement comme elles fonctionnent aujourd’hui et tous ces bénéfices viennent vers vous sans absolument aucune modification d’application. Activez un switch. Et cela fonctionne plus vite…
4. Le nouveau serveur M6-32

La suite de la Keynote présente la nouvelle machine M6-32. Une machine particulièrement adaptée pour le In-Memory Database, une machine avec 32 To de DRAM et 32 processeurs SPARC M6 disposant du double de cœurs que le M5 : 12 cœurs par processeur et 96 threads par processeur. Un billet prochainement sur cette partie de la Keynote dans notre blog ?
Conclusion
Ainsi se termine ce troisième et dernier billet sur la partie dédié à Oracle In-Memory 12c de la keynote présentée par Larry Ellison à Oracle Open World 2013 le 22/9/2013. Etes-vous aussi enthousiaste que DIGORA sur cette nouvelle technologie Oracle InMemory Database 12c ? Venez à la présentation Oracle du 18 juin pour en savoir beaucoup plus et bénéficier d'un retour client et de l'interview de Gilles Knoery, Directeur Général de Digora, sur les tests déjà réalisés sur cette option. Lien d’inscription pour cet événement : http://eventreg.oracle.com/profile/web/index.cfm?PKWebId=0x86964beb5 Nous allons très prochainement ajouter un billet dans notre blog concernant les "instructions-vecteurs SIMD" qui permettent ces performances étonnantes. Vous souhaitez mettre en oeuvre Oracle InMemory Database 12c rapidement ? Contactez-nous ici. Nous pouvons prendre RDV pour le 19 juin…  Index thématique du Blog Digora
Index thématique du Blog Digora
Pour aller plus loin

Blog
Sécurité
Données
Publié le 05/04/2024
Le PRA ou plan de reprise d’activité, plus que jamais d’actualité
Le Plan de Reprise d'Activité (PRA) est un document essentiel pour toute entreprise qui souhaite se prémunir contre les risques [...]
Lire la suite

